import pywikibot # load the whole library
# then we specifically import the page generator so we can iterate over all returned items
from pywikibot import pagegenerators as pg
# we query Wikidata directly, not the english language Wikipedia
wikidata_site = pywikibot.Site("wikidata", "wikidata")
# let's translate our query into SPARQL
QUERY = """
SELECT DISTINCT ?item
WHERE {
?item wdt:P31 wd:Q5; # Any instance of a human;
wdt:P106 wd:Q82955; # occupation politician;
wdt:P27 wd:Q114; # citizen of kenya;
}
LIMIT 5
"""Using Wikidata
Wikidata is a collaboratively maintained knowledge-base that is part of the larger Wikimedia universe and that includes more than 120,000,000 data entities. This data is also used to cross-link pages about the same subject across Wiki projects (like different language versions).
Main concepts
The knowledge-base of Wikidata consists of items that are further described by having properties which can have different values (these values in turn can be items too). Together properties and values make up statements about a given item
The Introduction to Wikidata uses this example to make it less abstract, using the British Science Fiction writer Douglas Adams as an example:
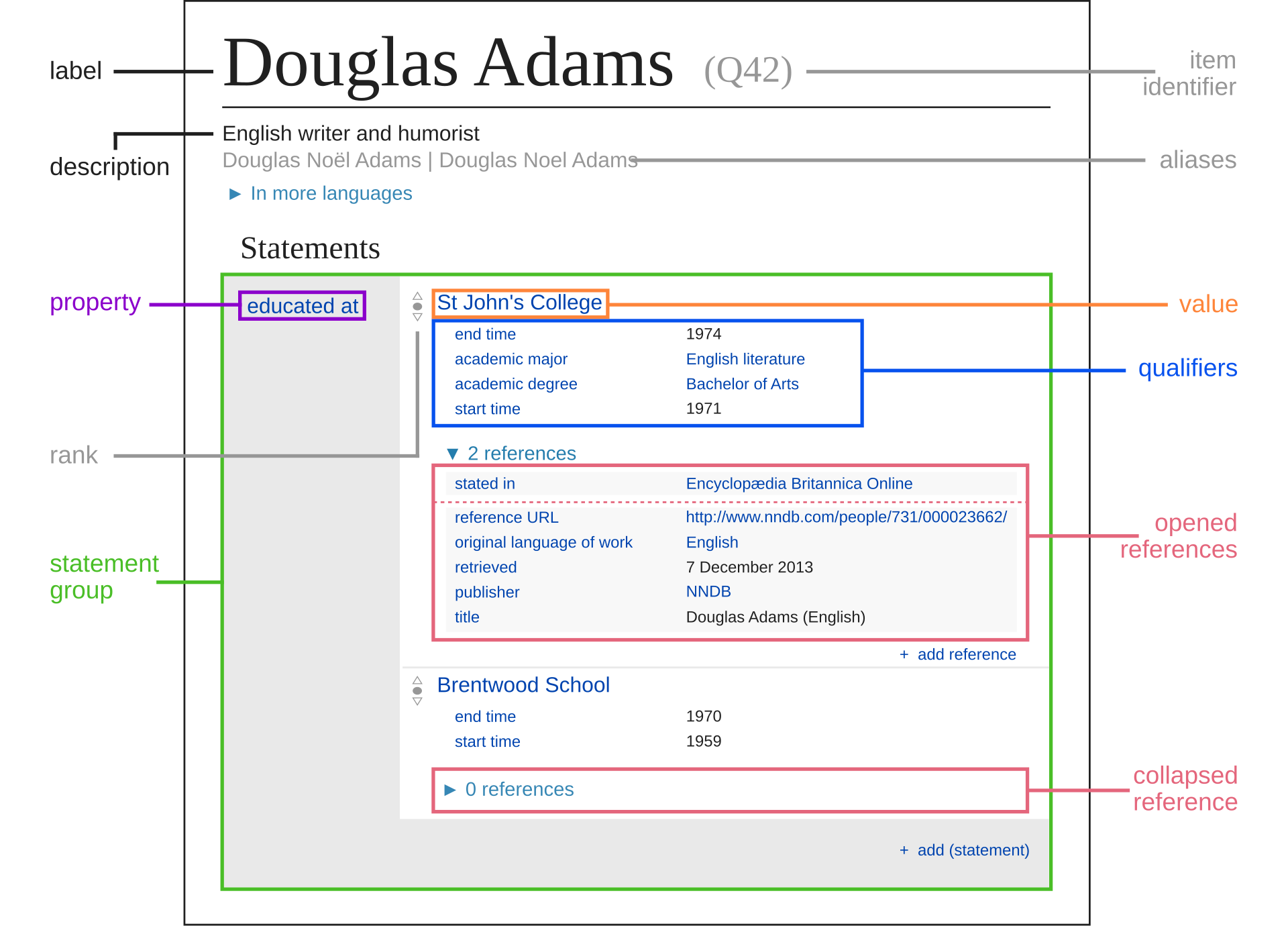
The highlighted statement (green) is about Adams’ education, shown as the educated_at property (violet) and gives two values for this, St John's College (demonstrated in orange) and Brentwood School. In this case, both of these values are Wikidata items themselves. But in other cases, this could also just be a simple value, e.g. a date for the birth date.
Each of those statements can also be further qualified and supported by references, depending on the property in question. Qualifications, like seen here, could be start/end dates, degrees, titles and more.
Wikidata can be queried using the SPARQL query language, which allows joining together required values for different properties to search for items.
Motivation
When we tried to find all Kenyan politicians, we used the Category:Kenyan politicians category of the English language Wikipedia as our starting point. But, this is not ideal as it will include false-positives, in the form of pages that are not actually articles that describe politicians, and false-negatives - that is actual pages from Kenyan politicians might be missing because they aren’t listed.
As an example for a false-positive when using the Category namespace: As there are many sub-categories for our category, we used recursion=True on the Category:Kenyan politicians, to make sure we get all the pages of politicians. But, our resulting list of pages surprisingly also includes the page about the Jomo Kenyatta International Airport!
Why? It’s because the page of the airport is part of the Category:Jomo Kenyatta, which in turn is part of Category:Presidents of Kenya, which in turn is part of Category:Political office-holders in Kenya, which - finally - is part of Category:Kenyan politicians.
Wikidata queries to find all pages of a type
By writing a more narrow query for Wikidata, we can avoid such false-positives – and also get a whole range of cross-links between the different Wiki projects, e.g. to find the English, and Swahili editions of the same article.
Writing a query
what properties and values could we use to find only Kenyan politicians?
- The articles should be about people, not airports. So we can filter to find items that describe humans only. If we search for this in Wikidata, we find that the corresponding property/value translates to
P31(instance of) and that humans are described by itemQ5. - Now, to find politicians, we can filter by finding items that additionally give the occupation
P106as politician (Q82955). - Lastly, we are looking for politicians that are from Kenya. One potential way to narrow it down to this could be filtering for the country of citizenship (
P27) to be Kenya (Q114).
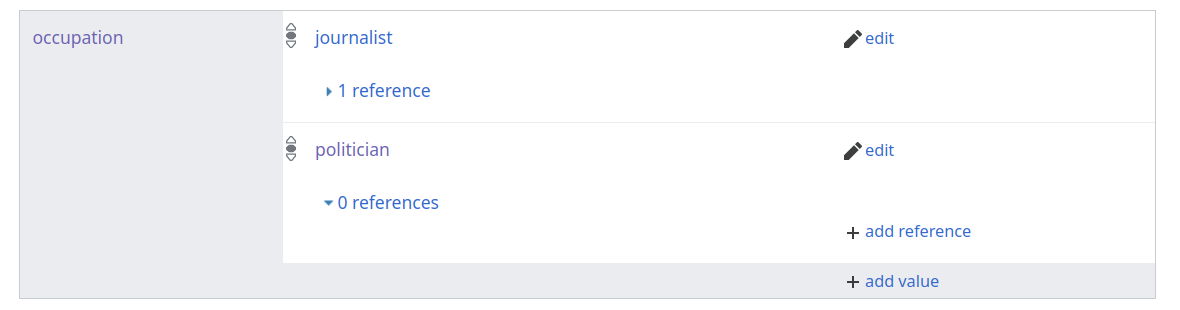
If we look at the Wikidata item for Jomo Kenyatta, we find those properties showing up like this:


Querying using pywikibot
Let’s now translate this into creating a SPARQL query that the pywikibot can run for us.
First, we load the necessary library again, and then we write out the query using the SPARQL syntax:
We use SELECT DISTINCT to avoid returning duplicate items, and use ?item to get the whole Wikidata item returned for further processing.
In the WHERE clause, we add our three distinct property/value pairs that we all want to be present, and ultimately give a LIMIT of how many Wikidata items we’d like to get returned.
Getting help writing queries
Wikimedia runs its own Query Service for Wikidata. You can use that to explore example queries and test browsers in a simpler interface to directly see if your query is well formatted and what it returns.
Once we got this query written, we can now turn this into a generator, that will allow us to make a loop over all returned elements.
We will already look at some of the data we get back:
generator = pg.WikidataSPARQLPageGenerator(QUERY, site=wikidata_site)
for item in generator:
print("item label (en): {}".format(
item.labels['en']
))
if 'en' in item.descriptions:
print("item description (en): {}".format(
item.descriptions['en']
))
print("sitelinks: {}".format(list(
item.sitelinks
)))
if 'enwiki' in item.sitelinks:
print("sitelink to enwiki: {}".format(
item.sitelinks["enwiki"]))
print("----------")item label (en): Elijah Lagat
item description (en): Kenyan marathon runner and politician
sitelinks: ['dewiki', 'enwiki', 'eswiki', 'itwiki', 'nlwiki', 'swwiki']
sitelink to enwiki: [[Elijah Lagat]]
----------
item label (en): Grace Emily Akinyi Ogot
item description (en): Kenyan politician and writer (1930-2015)
sitelinks: ['arwiki', 'arzwiki', 'dewiki', 'enwiki', 'enwikiquote', 'eowiki', 'fiwiki', 'frwiki', 'hawiki', 'hewiki', 'hywikisource', 'igwiki', 'igwikiquote', 'itwiki', 'lawiki', 'ptwiki', 'rowiki', 'sowiki', 'swwiki', 'tawiki', 'ukwiki', 'urwiki']
sitelink to enwiki: [[Grace Ogot]]
----------
item label (en): Newton Kulundu
item description (en): Kenyan politician (1948-2010)
sitelinks: ['dewiki', 'enwiki', 'ptwiki']
sitelink to enwiki: [[Newton Kulundu]]
----------
item label (en): Wesley Korir
item description (en): Kenyan marathon runner and politician
sitelinks: ['arwiki', 'arzwiki', 'commonswiki', 'dewiki', 'enwiki', 'fawiki', 'frwiki', 'mlwiki', 'nlwiki', 'nowiki', 'ptwiki', 'ruwiki']
sitelink to enwiki: [[Wesley Korir]]
----------
item label (en): David Lelei
item description (en): Kenyan distance runner (1971-2010)
sitelinks: ['arzwiki', 'dewiki', 'enwiki', 'eswiki', 'frwiki', 'nlwiki', 'ptwiki']
sitelink to enwiki: [[David Lelei]]
----------For many items, the labels and descriptions will be available in multiple languages. Here, we printed only the English one.
And as you see in the sitelinks, Wikidata also returns the cross-links to other Wiki projects, like the English (enwiki) and Swahili (swwiki) language editions of Wikipedia. This allows us now to switch to Wikipedia and read the articles as before.
Exploring what the most common language editions are
Let’s say we’re interested to explore how different politicians are represented (or not) across language editions. While there’s a large number of languages, let’s pick a small subset of languages to work with for this example. If you have languages you’re interest in, you can add them in the same format to the list, using the corresponding 2-letter ISO 639 language code.
languages = [
"enwiki",
"swwiki",
"dewiki",
"frwiki",
"eswiki",
]Let’s now expand our query a bit and get 20 entries for politicians instead of just 5, and then create a dataframe that contains the wiki-links for each of those combinations of politician & language-edition if present:
import pandas as pd # we'll need pandas to create the DF, your pandas version should be 2.1 or newer
QUERY = """
SELECT DISTINCT ?item
WHERE {
?item wdt:P31 wd:Q5; # Any instance of a human;
wdt:P106 wd:Q82955; # occupation politician;
wdt:P27 wd:Q114; # citizen of kenya;
}
LIMIT 20
"""
generator = pg.WikidataSPARQLPageGenerator(QUERY, site=wikidata_site)
politicians = {} # create an empty dictionary that will hold the names as keys, and another dictionary with {'enwiki': '$pagename', …}
for item in generator:
label = item.labels['en']
politicians[label] = {}
print('get languages for {}'.format(label))
sitelinks = item.sitelinks
for language in languages:
if language in sitelinks.keys():
politicians[label][language] = sitelinks[language].canonical_title()
else:
politicians[label][language] = ""
df_language_links = pd.DataFrame(politicians).T # use .T to transpose, so that policians are rows and languages are columns
df_language_linksget languages for Jomo Kenyatta
get languages for Wangari Muta Maathai
get languages for Elijah Lagat
get languages for William Ruto
get languages for Moses Wetangula
get languages for Harry Thuku
get languages for Grace Emily Akinyi Ogot
get languages for Wesley Korir
get languages for Daniel arap Moi
get languages for Moses Mudavadi
get languages for Uhuru Kenyatta
get languages for Raila A Odinga
get languages for McDonald Mariga
get languages for Richard Leakey
get languages for Newton Kulundu
get languages for Gitobu Imanyara
get languages for David Lelei
get languages for Abdilatif Abdalla
get languages for Mwai Kibaki
get languages for Kalonzo Musyoka| enwiki | swwiki | dewiki | frwiki | eswiki | |
|---|---|---|---|---|---|
| Jomo Kenyatta | Jomo Kenyatta | Jomo Kenyatta | Jomo Kenyatta | Jomo Kenyatta | Jomo Kenyatta |
| Wangari Muta Maathai | Wangarĩ Maathai | Wangari Maathai | Wangari Maathai | Wangari Muta Maathai | Wangari Maathai |
| Elijah Lagat | Elijah Lagat | Elijah Lagat | Elijah Lagat | Elijah Lagat | |
| William Ruto | William Ruto | William Ruto | William Ruto | William Ruto | William Ruto |
| Moses Wetangula | Moses Wetang'ula | Moses Wetangula | Moses Wetangula | Moses Wetangula | |
| Harry Thuku | Harry Thuku | Harry Thuku | Harry Thuku | ||
| Grace Emily Akinyi Ogot | Grace Ogot | Grace Ogot | Grace Ogot | Grace Ogot | |
| Wesley Korir | Wesley Korir | Wesley Korir | Wesley Korir | ||
| Daniel arap Moi | Daniel arap Moi | Daniel Arap Moi | Daniel arap Moi | Daniel arap Moi | Daniel arap Moi |
| Moses Mudavadi | Moses Mudavadi | Moses Mudavadi | |||
| Uhuru Kenyatta | Uhuru Kenyatta | Uhuru Kenyatta | Uhuru Kenyatta | Uhuru Kenyatta | Uhuru Kenyatta |
| Raila A Odinga | Raila Odinga | Raila Odinga | Raila Odinga | Raila Odinga | Raila Odinga |
| McDonald Mariga | McDonald Mariga | McDonald Mariga | McDonald Mariga | McDonald Mariga | McDonald Mariga |
| Richard Leakey | Richard Leakey | Richard Leakey | Richard Leakey | Richard Leakey | Richard Leakey |
| Newton Kulundu | Newton Kulundu | Newton Kulundu | |||
| Gitobu Imanyara | Gitobu Imanyara | Gitobu Imanyara | Gitobu Imanyara | ||
| David Lelei | David Lelei | David Lelei | David Lelei | David Lelei | |
| Abdilatif Abdalla | Abdilatif Abdalla | Abdilatif Abdalla | Abdilatif Abdalla | Abdilatif Abdalla | Abdilatif Abdalla |
| Mwai Kibaki | Mwai Kibaki | Mwai Kibaki | Mwai Kibaki | Mwai Kibaki | Mwai Kibaki |
| Kalonzo Musyoka | Kalonzo Musyoka | Kalonzo Musyoka | Kalonzo Musyoka | Kalonzo Musyoka |
This gives us a nice data frame that includes all the links to the different pages acrosst the target languages. Why did we decide to keep the actual links as values instead of directly just making a binary “yes/no” evaluation?
Because the actual names of the pages can differ between language editions, e.g. they can include middle names or add (politician) to the page name to disambigute multiple persons.
Which means if we want to keep working with the actual pages, we should keep those names to be able to query them.
But let’s now make a small presence/absence Matrix:
pam_df = df_language_links.map(lambda x: int(bool(x))) # create presence/absence matrix
pam_df.style.background_gradient(cmap ='viridis',axis=None) # use axis=None to display heatmap calculated across whole DF| enwiki | swwiki | dewiki | frwiki | eswiki | |
|---|---|---|---|---|---|
| Jomo Kenyatta | 1 | 1 | 1 | 1 | 1 |
| Wangari Muta Maathai | 1 | 1 | 1 | 1 | 1 |
| Elijah Lagat | 1 | 1 | 1 | 0 | 1 |
| William Ruto | 1 | 1 | 1 | 1 | 1 |
| Moses Wetangula | 1 | 1 | 1 | 1 | 0 |
| Harry Thuku | 1 | 0 | 1 | 1 | 0 |
| Grace Emily Akinyi Ogot | 1 | 1 | 1 | 1 | 0 |
| Wesley Korir | 1 | 0 | 1 | 1 | 0 |
| Daniel arap Moi | 1 | 1 | 1 | 1 | 1 |
| Moses Mudavadi | 1 | 0 | 1 | 0 | 0 |
| Uhuru Kenyatta | 1 | 1 | 1 | 1 | 1 |
| Raila A Odinga | 1 | 1 | 1 | 1 | 1 |
| McDonald Mariga | 1 | 1 | 1 | 1 | 1 |
| Richard Leakey | 1 | 1 | 1 | 1 | 1 |
| Newton Kulundu | 1 | 0 | 1 | 0 | 0 |
| Gitobu Imanyara | 1 | 1 | 0 | 1 | 0 |
| David Lelei | 1 | 0 | 1 | 1 | 1 |
| Abdilatif Abdalla | 1 | 1 | 1 | 1 | 1 |
| Mwai Kibaki | 1 | 1 | 1 | 1 | 1 |
| Kalonzo Musyoka | 1 | 1 | 1 | 1 | 0 |
This shows us some differences, both between individual politicians and the language editions, e.g. the Spanish Wikipedia has fewer articles for this set of politicians.
But how long are those articles? Let’s convert this into looking at length, instead of presence/absence. First we need to set up the different Site objects for the different languages, so that we can query those.
And then we re-use our existing politicians dictionary to query the WP API for the corresponding page lengths, and save those in a dictionary that we can ultimately convert into a DataFrame.
Note: Querying all of those pages across language editions can take some time due to API limits.
language_sites = {} # let's store the site objects in a dict, so we can use them for our queries
for language in languages:
language_sites[language] = pywikibot.Site(language[:2], 'wikipedia') # [:2] to get the language prefix
# for now we store the article lengths in a dict
article_lengths = {}
for politician in politicians:
article_lengths[politician] = {}
for language in politicians[politician]:
if politicians[politician][language]:
page = pywikibot.Page(language_sites[language], politicians[politician][language])
article_lengths[politician][language] = len(page.text)
else: # don't have a page, so length is zero
article_lengths[politician][language] = 0
df_article_length = pd.DataFrame(article_lengths).TNow that we got the data frame with article lengths, we can plot it as a heat map again.
The heatmap above was done over all cells. But to better compare the lengths within a language, we will now assign colors by column instead, i.e. language edition:
df_article_length.style.background_gradient(cmap ='viridis',axis=0)| enwiki | swwiki | dewiki | frwiki | eswiki | |
|---|---|---|---|---|---|
| Jomo Kenyatta | 154884 | 5528 | 25027 | 13234 | 15096 |
| Wangari Muta Maathai | 76445 | 3211 | 22759 | 27246 | 61486 |
| Elijah Lagat | 12564 | 1091 | 4761 | 0 | 5463 |
| William Ruto | 87708 | 8643 | 18334 | 19112 | 26486 |
| Moses Wetangula | 19496 | 2758 | 4878 | 2891 | 0 |
| Harry Thuku | 13230 | 0 | 3704 | 12453 | 0 |
| Grace Emily Akinyi Ogot | 16636 | 4621 | 4682 | 8000 | 0 |
| Wesley Korir | 16759 | 0 | 3764 | 9470 | 0 |
| Daniel arap Moi | 55812 | 10665 | 9839 | 8431 | 10622 |
| Moses Mudavadi | 985 | 0 | 1033 | 0 | 0 |
| Uhuru Kenyatta | 120687 | 8931 | 24740 | 26056 | 11713 |
| Raila A Odinga | 123275 | 10775 | 30587 | 53369 | 6078 |
| McDonald Mariga | 19953 | 4250 | 25325 | 7607 | 15887 |
| Richard Leakey | 44530 | 3165 | 10229 | 8184 | 20618 |
| Newton Kulundu | 4786 | 0 | 3386 | 0 | 0 |
| Gitobu Imanyara | 4593 | 4758 | 0 | 1856 | 0 |
| David Lelei | 5151 | 0 | 1779 | 3847 | 4818 |
| Abdilatif Abdalla | 4321 | 1564 | 3818 | 1056 | 3112 |
| Mwai Kibaki | 89924 | 10254 | 13499 | 9307 | 7643 |
| Kalonzo Musyoka | 28477 | 2510 | 2659 | 5503 | 0 |
Working with claims
Now that we have seen how we can bridge between Wikidata items and Wikipedia pages, let us see how we can explore the Wikidata knowledge graph a bit more beyond just getting the objects and cross-links.
One thing that many Wikidata items about people contain, is the gender of the person they describe, which we need if we want to explore if Wikipedia articles describing people’s biographies differ between gender of the person.
Inferring a person’s gender is a fraught effort, and misclassifications are not distributed amongst race or ethnicity. In Wikidata knowledge graph, gender is represented by property P21 (technically, Wikidata translates that to sex or gender), which would allow
To get explore this, let’s query a single politician using the same query as before and use that Wikidata item to explore the knowledge graph:
QUERY = """
SELECT DISTINCT ?item
WHERE {
?item wdt:P31 wd:Q5; # Any instance of a human;
wdt:P106 wd:Q82955; # occupation politician;
wdt:P27 wd:Q114; # citizen of kenya;
}
LIMIT 1
"""
generator = pg.WikidataSPARQLPageGenerator(QUERY, site=wikidata_site)
wikidata_item = generator.__next__() # to just emit the single response
print('got {} as politician'.format(wikidata_item.labels['en'])) got Moses Mudavadi as politicianNow that we got our wikidata item, let’s find out if it contains claim about the person’s gender:
# p21: gender
# [0] get the first claim for this property - for some properties there could be multiple claims!
# target: Get the value of that claim - can be an item too
# label: get english name of item, i.e. gender marker in english
wikidata_item.claims['P21'][0].target.labels['en']'male'Let’s look at this step by step:
-
.claims['P21']asks to get all values of this property for our Wikidata item of interest. Items can have zero to many claims for a given property. We need to consider this when doing error handling. -
[0]- we are interested in only looking at the first value for this property, in case there’d be multiple. Of course, depending on the property, we could be interested at looking at all of them! -
.targetgives us the actual value of that claim. Forgenderthis will be another Wikidata item, which has translatable labels
Bringing it together
Now, let’s try to get a set of politicians, their gender according to Wikidata and then get the page lengths for the diferrent language editions. We can then do a simple comparison between article length and gender in those languages:
QUERY = """
SELECT DISTINCT ?item
WHERE {
?item wdt:P31 wd:Q5; # Any instance of a human;
wdt:P106 wd:Q82955; # occupation politician;
wdt:P27 wd:Q114; # citizen of kenya;
}
LIMIT 10
"""
LANGUAGES = [
"enwiki",
"swwiki",
"dewiki",
"frwiki",
"eswiki",
]
LANGUAGE_SITES = {} # let's store the site objects in a dict, so we can use them for our queries
for language in LANGUAGES:
LANGUAGE_SITES[language] = pywikibot.Site(language[:2], 'wikipedia') # [:2] to get the language prefix
# Let's wrap some of the code we wrote above into functions, to make it easier to call and ultimately merge it into a dataframe at the end!
def get_gender(wikidata_item):
if "P21" in wikidata_item.claims.keys():
return wikidata_item.claims['P21'][0].target.labels['en']
else:
return "unknown"
def run_query(QUERY):
generator = pg.WikidataSPARQLPageGenerator(QUERY, site=wikidata_site)
politician_data = {}
for item in generator:
qid = item.getID() # get unique ID
politician_data[qid] = {} # initialize dictionary
politician_data[qid]['gender'] = get_gender(item) # add gender
politician_data[qid]['label'] = item.labels['en'] # add english label
print('get languages for {}'.format(qid))
sitelinks = item.sitelinks
for language in LANGUAGES:
if language in sitelinks.keys():
page_title = sitelinks[language].canonical_title()
page = pywikibot.Page(LANGUAGE_SITES[language], page_title)
politician_data[qid][language] = len(page.text)
else: # don't have a page, so length is zero
politician_data[qid][language] = 0
return politician_datapolitician_data = run_query(QUERY)
pd.DataFrame(politician_data).Tget languages for Q173563
get languages for Q193492
get languages for Q308189
get languages for Q313893
get languages for Q46795
get languages for Q202077
get languages for Q318960
get languages for Q195725
get languages for Q121708
get languages for Q196070| gender | label | enwiki | swwiki | dewiki | frwiki | eswiki | |
|---|---|---|---|---|---|---|---|
| Q173563 | male | Jomo Kenyatta | 154884 | 5528 | 25027 | 13234 | 15096 |
| Q193492 | male | Daniel arap Moi | 55812 | 10665 | 9839 | 8431 | 10622 |
| Q308189 | male | Abdilatif Abdalla | 4321 | 1564 | 3818 | 1056 | 3112 |
| Q313893 | male | McDonald Mariga | 19953 | 4250 | 25325 | 7607 | 15887 |
| Q46795 | female | Wangari Muta Maathai | 76445 | 3211 | 22759 | 27246 | 61486 |
| Q202077 | male | Harry Thuku | 13230 | 0 | 3704 | 12453 | 0 |
| Q318960 | male | Richard Leakey | 44530 | 3165 | 10229 | 8184 | 20618 |
| Q195725 | male | William Ruto | 87708 | 8643 | 18334 | 19112 | 26486 |
| Q121708 | male | Moses Mudavadi | 985 | 0 | 1033 | 0 | 0 |
| Q196070 | male | Uhuru Kenyatta | 120687 | 8931 | 24740 | 26056 | 11713 |
While this form of querying works, it shows quite a heavy gender bias (which could be in politics, in Wikipedia, or both?). Either way, by querying without gender, we end up with an overwhelmingly male data set.
To be able to actually make a comparison, let’s do two queries instead, one for male and one for female politicians:
male_query = """
SELECT DISTINCT ?item
WHERE {
?item wdt:P31 wd:Q5; # Any instance of a human;
wdt:P106 wd:Q82955; # occupation politician;
wdt:P27 wd:Q114; # citizen of kenya;
wdt:P21 wd:Q6581097; # male
}
LIMIT 20
"""
female_query = """
SELECT DISTINCT ?item
WHERE {
?item wdt:P31 wd:Q5; # Any instance of a human;
wdt:P106 wd:Q82955; # occupation politician;
wdt:P27 wd:Q114; # citizen of kenya;
wdt:P21 wd:Q6581072; # female
}
LIMIT 20
"""
male_politicians = run_query(male_query)
female_politicians = run_query(female_query)
get languages for Q173563
get languages for Q710549
get languages for Q346046
get languages for Q1441663
get languages for Q195725
get languages for Q733817
get languages for Q202077
get languages for Q593552
get languages for Q447119
get languages for Q193492
get languages for Q121708
get languages for Q196070
get languages for Q457713
get languages for Q1372633
get languages for Q645228
get languages for Q456466
get languages for Q308189
get languages for Q743818
get languages for Q733180
get languages for Q1395018
get languages for Q46795
get languages for Q16886393
get languages for Q47489052
get languages for Q47490030
get languages for Q47490021
get languages for Q47486849
get languages for Q469641
get languages for Q16734504
get languages for Q16886147
get languages for Q16842239
get languages for Q47490034
get languages for Q539821
get languages for Q16885582
get languages for Q565671
get languages for Q44090439
get languages for Q47489991
get languages for Q47490033
get languages for Q16866530
get languages for Q47483883
get languages for Q16886400Now we can merge the two dictionaries and create one dataframe:
all_politicians = female_politicians | male_politicians
df_all_politicians = pd.DataFrame(all_politicians).T
df_all_politicians| gender | label | enwiki | swwiki | dewiki | frwiki | eswiki | |
|---|---|---|---|---|---|---|---|
| Q46795 | female | Wangari Muta Maathai | 76445 | 3211 | 22759 | 27246 | 61486 |
| Q16886393 | female | Anne Waiguru | 16354 | 4402 | 0 | 0 | 0 |
| Q47489052 | female | Gladys Wanga | 5150 | 1417 | 0 | 0 | 0 |
| Q47490030 | female | Catherine Nanjala Wambilianga | 2536 | 690 | 0 | 0 | 0 |
| Q47490021 | female | Joyce Chepkoech Korir | 4077 | 645 | 0 | 0 | 0 |
| Q47486849 | female | Gertrude Mbeyu Mwanyanje | 1293 | 0 | 0 | 0 | 0 |
| Q469641 | female | Grace Emily Akinyi Ogot | 16636 | 4621 | 4682 | 8000 | 0 |
| Q16734504 | female | Phyllis Kandie | 9499 | 0 | 0 | 0 | 0 |
| Q16886147 | female | Peris Tobiko | 5914 | 5274 | 0 | 0 | 0 |
| Q16842239 | female | Sonia Birdi | 6330 | 1647 | 0 | 0 | 0 |
| Q47490034 | female | Jane Wanjuki Njiru | 4486 | 933 | 0 | 0 | 0 |
| Q539821 | female | Charity Ngilu | 23356 | 1772 | 2740 | 10607 | 1800 |
| Q16885582 | female | Naomi Shaban | 3471 | 793 | 0 | 0 | 0 |
| Q565671 | female | Anne Nyokabi Muhoho | 2144 | 0 | 0 | 0 | 0 |
| Q44090439 | female | Roslyne Akombe | 11692 | 613 | 0 | 0 | 0 |
| Q47489991 | female | Gladwell Jesire Cheruiyot | 4350 | 1342 | 0 | 0 | 0 |
| Q47490033 | female | Jane Jepkorir Kiptoo Chebaibai | 4073 | 0 | 0 | 0 | 0 |
| Q16866530 | female | Margaret Gakuo Kenyatta | 5542 | 0 | 8273 | 5127 | 0 |
| Q47483883 | female | Elsie Busihile Muhanda | 1930 | 0 | 0 | 0 | 0 |
| Q16886400 | female | Judy Wakhungu | 17234 | 1778 | 0 | 0 | 0 |
| Q173563 | male | Jomo Kenyatta | 154884 | 5528 | 25027 | 13234 | 15096 |
| Q710549 | male | Arthur Magugu | 1125 | 920 | 1201 | 0 | 1835 |
| Q346046 | male | Elijah Lagat | 12564 | 1091 | 4761 | 0 | 5463 |
| Q1441663 | male | Francis Muthaura | 11033 | 0 | 2896 | 1359 | 0 |
| Q195725 | male | William Ruto | 87708 | 8643 | 18334 | 19112 | 26486 |
| Q733817 | male | George Saitoti | 50502 | 5149 | 3978 | 6445 | 1868 |
| Q202077 | male | Harry Thuku | 13230 | 0 | 3704 | 12453 | 0 |
| Q593552 | male | Michael Kijana Wamalwa | 8368 | 5503 | 3166 | 0 | 0 |
| Q447119 | male | Wesley Korir | 16759 | 0 | 3764 | 9470 | 0 |
| Q193492 | male | Daniel arap Moi | 55812 | 10665 | 9839 | 8431 | 10622 |
| Q121708 | male | Moses Mudavadi | 985 | 0 | 1033 | 0 | 0 |
| Q196070 | male | Uhuru Kenyatta | 120687 | 8931 | 24740 | 26056 | 11713 |
| Q457713 | male | Newton Kulundu | 4786 | 0 | 3386 | 0 | 0 |
| Q1372633 | male | Gitobu Imanyara | 4593 | 4758 | 0 | 1856 | 0 |
| Q645228 | male | Jaramogi Oginga Odinga | 14768 | 4219 | 3711 | 15220 | 2581 |
| Q456466 | male | David Lelei | 5151 | 0 | 1779 | 3847 | 4818 |
| Q308189 | male | Abdilatif Abdalla | 4321 | 1564 | 3818 | 1056 | 3112 |
| Q743818 | male | David Kimutai Too | 4976 | 0 | 1562 | 7618 | 0 |
| Q733180 | male | Tom Mboya | 24597 | 10552 | 6843 | 18019 | 0 |
| Q1395018 | male | Kalonzo Musyoka | 28477 | 2510 | 2659 | 5503 | 0 |
Now let’s try plotting this as a boxplot, grouping by gender for each of the languages:
df_all_politicians.plot(kind='box',column=LANGUAGES, by=["gender"],layout=(5, 1),figsize=(10,15))dewiki Axes(0.125,0.747241;0.775x0.132759)
enwiki Axes(0.125,0.587931;0.775x0.132759)
eswiki Axes(0.125,0.428621;0.775x0.132759)
frwiki Axes(0.125,0.26931;0.775x0.132759)
swwiki Axes(0.125,0.11;0.775x0.132759)
dtype: object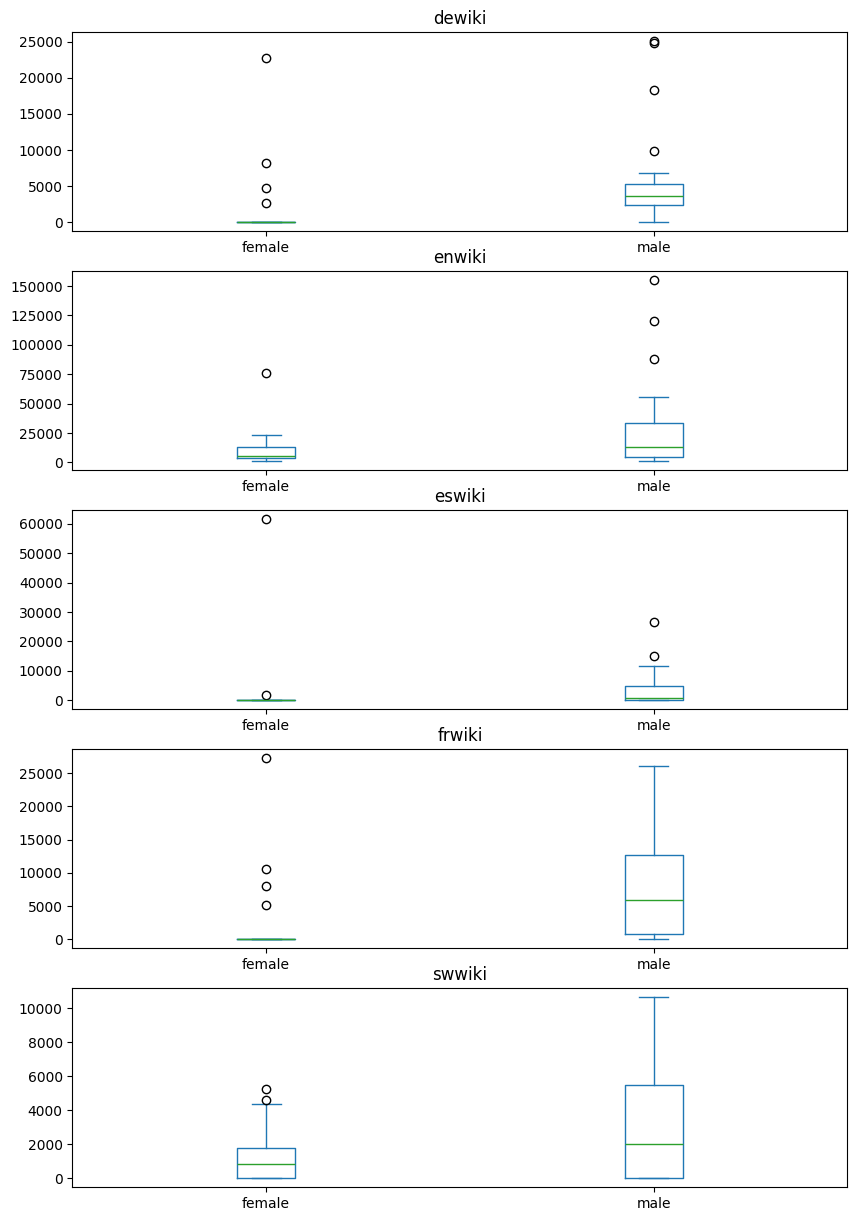
Exploring the difference in number of pages by gender
Let’s also investigate how large the difference in number of recorded items is for male & female politicians in Wikidata. For that we can run two queries to just get the number of items:
SELECT DISTINCT (COUNT(?item) as ?count) # get count of items instead of actual pages
WHERE {
?item wdt:P31 wd:Q5; # Any instance of a human;
wdt:P106 wd:Q82955; # occupation politician;
wdt:P27 wd:Q114; # citizen of kenya;
wdt:P21 wd:Q6581097; # male
}and
SELECT DISTINCT (COUNT(?item) as ?count) # get count of items instead of actual pages
WHERE {
?item wdt:P31 wd:Q5; # Any instance of a human;
wdt:P106 wd:Q82955; # occupation politician;
wdt:P27 wd:Q114; # citizen of kenya;
wdt:P21 wd:Q6581072; # female
}We can run these directly using the Wikidata Query Service, without having to write code (e.g. for male and female politicians): This shows us that there are 224 items for female politicians, and 915 items for male politicians.
Using some very basic NLP to identify a gender from a Wikipedia page
So far, we have used the gender information as directly supplied by Wikidata (and even explicitly filtered for the presence of the information). But potentially this information is not present in all Wikidata items describing politicians.
Plus, if we think back to just querying category pages - we might want to also use Wikipedia pages directly, without expecting or needing a corresponding Wikidata item. How could we assign gender in that case? A ver simple example would be to count the pronouns in each page and use those to assign gender.
We can try to explore how well such an approach would work by using our existing set of politicians, loading the (English) articles and giving it a try:
wikidata_site = language_sites['enwiki'].data_repository() # setup wikidata site object
pronouns_female = ['she', 'her', 'herself', 'hers']
pronouns_male = ['he', 'him', 'himself', 'his']
pronoun_female_count = []
pronoun_male_count = []
for qid in df_all_politicians.index: # iterate over all qid which we so far used as df index
if 'enwiki' in pywikibot.ItemPage(wikidata_site, qid).sitelinks.keys(): # not all wikidata items have english language articles
article_title = pywikibot.ItemPage(wikidata_site, qid).sitelinks['enwiki'].canonical_title() # get english page title
page = pywikibot.Page(LANGUAGE_SITES['enwiki'], article_title) # get article text
page_text = page.text.lower() # make lower case to simplify matching
# sum up female pronoun counts, add to list
counts_female = 0
for p in pronouns_female:
counts_female += page_text.count(" {} ".format(p)) # require space before/after pronoun
pronoun_female_count.append(counts_female)
# sum up female pronoun counts, add to list
counts_male = 0
for p in pronouns_male:
counts_male += page_text.count(" {} ".format(p))
pronoun_male_count.append(counts_male)
else:
pronoun_female_count.append(0)
pronoun_male_count.append(0)
# add pronouns to DF
df_all_politicians['pronoun_female_count'] = pronoun_female_count
df_all_politicians['pronoun_male_count'] = pronoun_male_countdf_all_politicians| gender | label | enwiki | swwiki | dewiki | frwiki | eswiki | pronoun_female_count | pronoun_male_count | |
|---|---|---|---|---|---|---|---|---|---|
| Q46795 | female | Wangari Muta Maathai | 76445 | 3211 | 22759 | 27246 | 61486 | 193 | 13 |
| Q16886393 | female | Anne Waiguru | 16354 | 4402 | 0 | 0 | 0 | 37 | 1 |
| Q47489052 | female | Gladys Wanga | 5150 | 1417 | 0 | 0 | 0 | 10 | 0 |
| Q47490030 | female | Catherine Nanjala Wambilianga | 2536 | 690 | 0 | 0 | 0 | 3 | 0 |
| Q47490021 | female | Joyce Chepkoech Korir | 4077 | 645 | 0 | 0 | 0 | 6 | 0 |
| Q47486849 | female | Gertrude Mbeyu Mwanyanje | 1293 | 0 | 0 | 0 | 0 | 1 | 0 |
| Q469641 | female | Grace Emily Akinyi Ogot | 16636 | 4621 | 4682 | 8000 | 0 | 40 | 2 |
| Q16734504 | female | Phyllis Kandie | 9499 | 0 | 0 | 0 | 0 | 14 | 1 |
| Q16886147 | female | Peris Tobiko | 5914 | 5274 | 0 | 0 | 0 | 47 | 2 |
| Q16842239 | female | Sonia Birdi | 6330 | 1647 | 0 | 0 | 0 | 12 | 0 |
| Q47490034 | female | Jane Wanjuki Njiru | 4486 | 933 | 0 | 0 | 0 | 10 | 0 |
| Q539821 | female | Charity Ngilu | 23356 | 1772 | 2740 | 10607 | 1800 | 45 | 5 |
| Q16885582 | female | Naomi Shaban | 3471 | 793 | 0 | 0 | 0 | 10 | 0 |
| Q565671 | female | Anne Nyokabi Muhoho | 2144 | 0 | 0 | 0 | 0 | 7 | 0 |
| Q44090439 | female | Roslyne Akombe | 11692 | 613 | 0 | 0 | 0 | 32 | 7 |
| Q47489991 | female | Gladwell Jesire Cheruiyot | 4350 | 1342 | 0 | 0 | 0 | 13 | 0 |
| Q47490033 | female | Jane Jepkorir Kiptoo Chebaibai | 4073 | 0 | 0 | 0 | 0 | 14 | 0 |
| Q16866530 | female | Margaret Gakuo Kenyatta | 5542 | 0 | 8273 | 5127 | 0 | 9 | 0 |
| Q47483883 | female | Elsie Busihile Muhanda | 1930 | 0 | 0 | 0 | 0 | 8 | 0 |
| Q16886400 | female | Judy Wakhungu | 17234 | 1778 | 0 | 0 | 0 | 26 | 0 |
| Q173563 | male | Jomo Kenyatta | 154884 | 5528 | 25027 | 13234 | 15096 | 12 | 490 |
| Q710549 | male | Arthur Magugu | 1125 | 920 | 1201 | 0 | 1835 | 0 | 2 |
| Q346046 | male | Elijah Lagat | 12564 | 1091 | 4761 | 0 | 5463 | 0 | 31 |
| Q1441663 | male | Francis Muthaura | 11033 | 0 | 2896 | 1359 | 0 | 0 | 28 |
| Q195725 | male | William Ruto | 87708 | 8643 | 18334 | 19112 | 26486 | 1 | 129 |
| Q733817 | male | George Saitoti | 50502 | 5149 | 3978 | 6445 | 1868 | 0 | 86 |
| Q202077 | male | Harry Thuku | 13230 | 0 | 3704 | 12453 | 0 | 0 | 27 |
| Q593552 | male | Michael Kijana Wamalwa | 8368 | 5503 | 3166 | 0 | 0 | 0 | 38 |
| Q447119 | male | Wesley Korir | 16759 | 0 | 3764 | 9470 | 0 | 0 | 56 |
| Q193492 | male | Daniel arap Moi | 55812 | 10665 | 9839 | 8431 | 10622 | 5 | 88 |
| Q121708 | male | Moses Mudavadi | 985 | 0 | 1033 | 0 | 0 | 0 | 3 |
| Q196070 | male | Uhuru Kenyatta | 120687 | 8931 | 24740 | 26056 | 11713 | 1 | 147 |
| Q457713 | male | Newton Kulundu | 4786 | 0 | 3386 | 0 | 0 | 0 | 11 |
| Q1372633 | male | Gitobu Imanyara | 4593 | 4758 | 0 | 1856 | 0 | 0 | 16 |
| Q645228 | male | Jaramogi Oginga Odinga | 14768 | 4219 | 3711 | 15220 | 2581 | 0 | 42 |
| Q456466 | male | David Lelei | 5151 | 0 | 1779 | 3847 | 4818 | 0 | 8 |
| Q308189 | male | Abdilatif Abdalla | 4321 | 1564 | 3818 | 1056 | 3112 | 0 | 17 |
| Q743818 | male | David Kimutai Too | 4976 | 0 | 1562 | 7618 | 0 | 1 | 9 |
| Q733180 | male | Tom Mboya | 24597 | 10552 | 6843 | 18019 | 0 | 0 | 65 |
| Q1395018 | male | Kalonzo Musyoka | 28477 | 2510 | 2659 | 5503 | 0 | 0 | 56 |
Now we got the absolute counts. For demonstration purposes, let’s now just make a very simple classifer, in which we assign the gender based on simple majority:
def assign_gender(row):
if row['pronoun_male_count'] != 0 and row['pronoun_female_count'] != 0:
ratio = row['pronoun_female_count'] / row['pronoun_male_count']
if ratio > 1:
return 'female'
else:
return 'male'
elif row['pronoun_male_count'] != 0:
return 'male'
else:
return 'female'
df_all_politicians['gender_nlp'] = df_all_politicians.apply(assign_gender,axis=1)We can now compare if the wikidata label and our prediction agree:
df_all_politicians['gender'] == df_all_politicians['gender_nlp']Q46795 True
Q16886393 True
Q47489052 True
Q47490030 True
Q47490021 True
Q47486849 True
Q469641 True
Q16734504 True
Q16886147 True
Q16842239 True
Q47490034 True
Q539821 True
Q16885582 True
Q565671 True
Q44090439 True
Q47489991 True
Q47490033 True
Q16866530 True
Q47483883 True
Q16886400 True
Q173563 True
Q710549 True
Q346046 True
Q1441663 True
Q195725 True
Q733817 True
Q202077 True
Q593552 True
Q447119 True
Q193492 True
Q121708 True
Q196070 True
Q457713 True
Q1372633 True
Q645228 True
Q456466 True
Q308189 True
Q743818 True
Q733180 True
Q1395018 True
dtype: boolWe see, that in this case, the naive classification seems to have mostly worked, but of course that is far from guaranteed!